
Non-local Neural Network was one of the outstanding model for video understanding and classification. The main contributions of the paper is to introduce a non-local operator that can...
•
efficiently capturing spatial features
•
Easily inserted to any network architecture
Non-local Mean
The idea of non-local neural network is from non-local means(NLM) algorithm, which is one of the edge-preserving denoise algorithms.
The paper compares the non-local mean operation to conv and fc layer. The advantage that the NLM has is that all pixels (or channels) of the image are weighed for each pixel denoising. This is different from the conv layer which only search a local pixels(e.g. kernel size) which is its common limitation. Also NLM is different to conv and fc layer in perspective of learning. When conv and fc layer have to learn weights (and biases), NLM returns a fixed value of relation of pixels. Also note the fact that NLM can deal with variable-size inputs. By this NLM's advantages, NLM is expected to enhance the receptive field for vision models.
Non-local Block and Self-attention
NLM requires a distance metric to determine the weight for each pixel. There are multiple candidates but ends up the candidates gives similar contribution to the performance improvement. However, the most interesting part when using the Embedding Gaussian as the metric.
Above is the formula for the embedding gaussian. Each pixels and are embedded into each embedding. The fact is, this formula can be expressed as a self-attention module. This is possible by thinking the exponential as the softmax function.
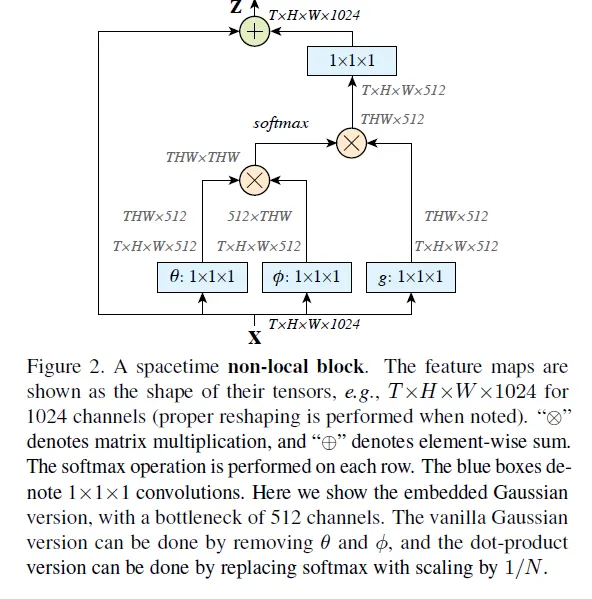
Thanks to the residual connection, this module can be inserted inbetween the layers. The paper calls this a Non-local Block and provides various tests to provide the way of the efficient use of the self-attention module.
Results
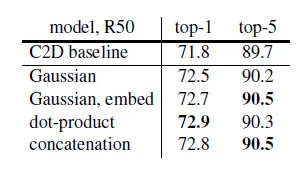
This result shows that the distance metric for NLM operator does not effect the performance much.
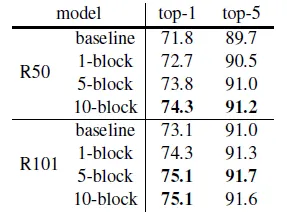
When inserting more NLM operator blocks to the Resnet, we can see that more non-local blocks with deeper network shows better result
This shows that the non-local block is effective in terms of spatial features.
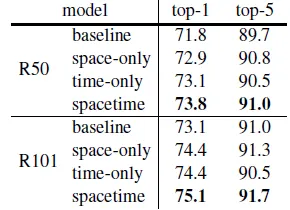
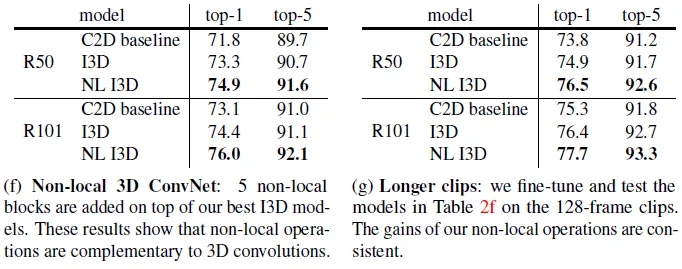
For results of video classification models w.w/o non-local blocks, the paper shows that non-local block gives significant performance boost to the video model (I3D).
Conclusion
I think non-local block can be popular since it is easy to insert as a module and can cover the limits of conv layers. I think for my research, I would use this non-local blocks in order to archieve minor improvement for denoisng. However still the question of modulating auxiliary features is an issue. Can attention-like architecture can handle this?
