
The paper proposes an advanced MC denoiser based on a single-frame MC denoiser by Bako et al[2017]. The paper's contribution is the following
1.
Source-encoder that can deal with inputs from various renderers
2.
Including temporal features from consecutive frames for reconstruction
3.
Multi-scale architecture for low-frequency detail reconstruction
4.
Asymmetric loss function for detail-preservance with run-time control
5.
Adaptive sampling using error-predicting network.
Note that the denoiser is about predicting a kernel that will be applied to the noisy image for reconstruction, not directly predicting denoised pixels.
Single frame denoiser
For a single frame denoiser, the paper adopted residual blocks with two conv layers and one skip connection. This is different from Bako et al which uses simple conv layers for extraction. Note that before extraction the source encoder deals with the discrepancy of input frames rendered by different renderers.
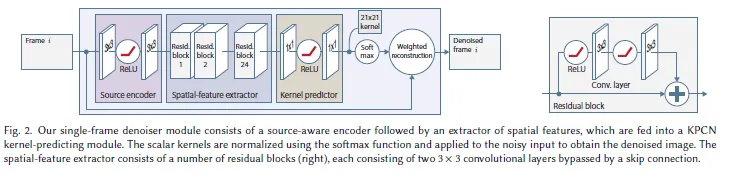
Temporal Denoiser
Using temporal features when denoising helps handling time-dependent effects such as flickering. To get advantage by using the temporal features, the paper applied extractor for each consecutive frames. Then extracted features are passed to temporal feature extractor. Then the predicted kernel will be provided for every frame input. These will be modified with the motion vector for temporal consistency, and then applied to each frame and aggregated for the final denoised result. The point it that unlike Chaitanya et al (2017), the paper's temporal denoiser accumulates features from both the past and future frames.
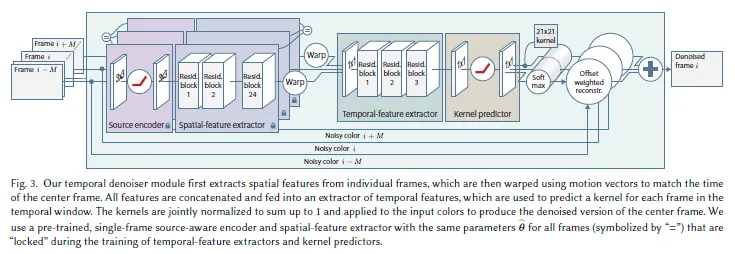
Multi-scale Architecture
Using a fixed sized (quite small) kernel for reconstruction helps to denoise high frequecny details, but is likely to lose low frequency details. So the paper introduces three-level denoiser architecture. The module gets the downsampled frame as an input and the denoiser above (either single-frame or temporal) denoises the input. Then the results are upscaled and accumulated through the compositor. This allows the kernel predicting denoiser to deal with spatially-dependent low freqeucny details.
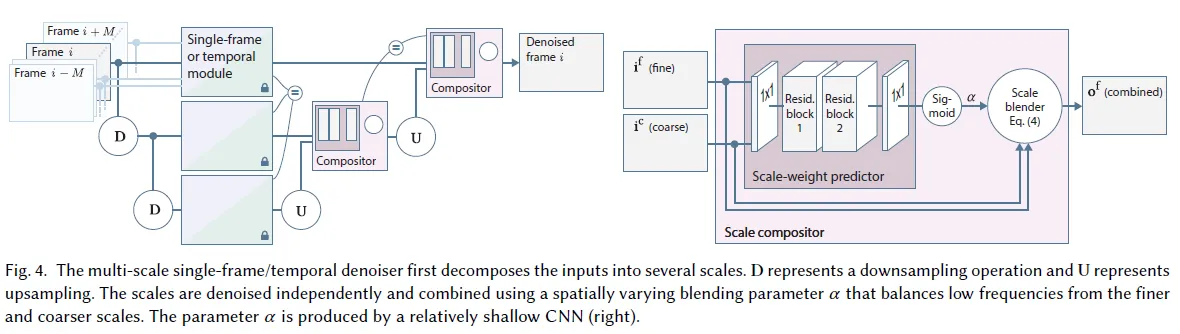
Assymetric Loss Function
This is one of the distinct part of the paper compared to any other DL based denoisers. There is always a tradeoff between denoising and preserving the detail. Overwhelmingly denoised result might produce a blurry image with lost details, when less denoising preserves original details when still having noise. Assymetric loss function allows the user to decide how much to preserve the details when denoising.
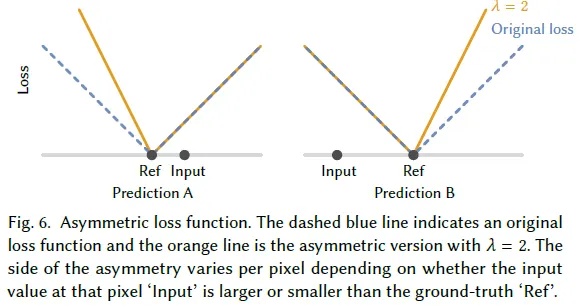
As in the figure above, the assymetric loss function penalizes the denoised result when the result is in the opposite direction in the image space of the input respect to the ground truth. This helps the model to more likely to produce denoised result preserves details from the input. The magnitude of penalization can be modulated by the factor lambda. Either the model can be trained on the fixed lambda, or can also get an input of lambda. The latter case can let the user to freely choose the lambda value (which will mean how much one would like to preserve the details) when denoising on run-time.
Adaptive Sampling
The paper also used error-predicting network that can be used for adaptive sampling.
Experiment
Paper used auxiliary features along with color in log scale...
•
relative color variance (1)
•
albedo log scale (3)
•
relative albedo variance (1)
•
normal (3)
•
relative normal variance (1)
Relaive variance : pixel variance divided into squared sample mean
Paper followed the pipeline similar to Bako et al. (2017) training for diffuse & specular effects each. However the difference is that the paper trained each effect on a same model with a flag that indicates the irradiance decomposition.
Results
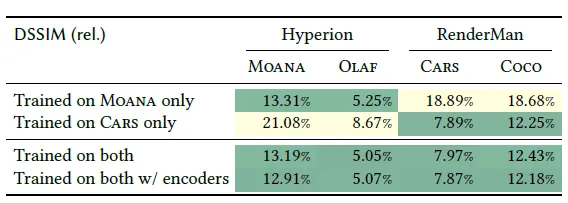
Source Encoder
When training with frames from two renderers with the source-aware encoder it showed the best result.
Temporal Denoising
The paper showed that temporal denoiser reduced the temporal instability of the reconstructed image. Also showed that using both frames from past and future symmetrically giving better result compared to Chaitanya et al. (2017)

Multi-scale Architecture
Multi-scale denosing helped to give best reconstructed results when using smaller kernel size.

Assymetric Loss
We can see that increasing lambda (making the filter conservative) makes the result contain more similar lighting details with the reference.

Adaptive Sampling
Paper showed that the introduced error-predicting module showed similar distribution of samples compared to the ground truth with par-result.

KPCN Convergence
Paper says that the model converged faster than the model of Bako et al. 2017. Also the paper gave the theorhetical proof that kernel-prediction converges expoenetially faster than direct prediction.
