My Thoughts
•
It was hard to think of the demand for continuous technique space in rendering, but this paper has shown its various applications. Great work.
•
However, to achieve unbiasedness there still requires some computation, especially PDF computation. For expensive BSDF this might take a long time.
•
Also, the paper compares the path-space filtering with quite out-of-time work. This makes the result and the performance less outstanding. However it’s understandable since there are not much path-reuse works directly working on samples and paths.
Review (Discrete) Multiple Importance Sampling (DMIS)
Given the following rendering equation (only scattering) and an Estimator.
Usually starting with two sampling strategies
•
BSDF Sampling
probability density set proportional to BSDF , or any other BSDF approximation
good for highly polished BSDF
bad for extreme light sources (small, multiple light sources)
•
Direct light sampling
among visible light sources, choose the point
good for dealing with various light sources
bad for complex BSDF
Among these, there can be various ways to choose the sampling domain and sampling density for a certain integrand.
How can we combine the samples from these various sampling properties with the least variance?
Given an integral and an estimator:
Multi-sample estimator is as below:
The weight function balances the contribution of each sample of sampling density . For unbiasedness, the weight function should follow the properties
It is known that the following balancing heuristics gives the least variance for multiple-sample estimator
Continuous Multiple Importance Sampling (CMIS)
Conventional DMIS deals with fixed number of sampling strategies. The paper extends the sampling strategies into a continuous space, where sampling strategies are in the continuous technique space .
Then the integral and the estimator can be written as below
is the probability of sampling a technique , is the probability of sampling point x, and is a joint PDF.
Similary to DMIS, weight function of CMIS also shares the similar condition
Also similary to DMIS, CMIS shows less variance when using balance heuristics instead of uniform weight.
By doing so, CMIS can deal withan uncountable set of sampling techniques, while DMIS can deal witha countable infinite set of techniques by
Stochastic Multiple Importance Sampling (SMIS)
However, calculating the weight function requires the computation of the marginal PDF of in the denominator. As always, integration on arbitrary PDF is most unlikely to be done in closed form.
Therefore, this paper approximates it as an average of existing samples , similar to sample-reuse techniques of .
LHS refers to n-sample CMIS, and RHS refers to the approximation with SMIS.
And the estimator becomes
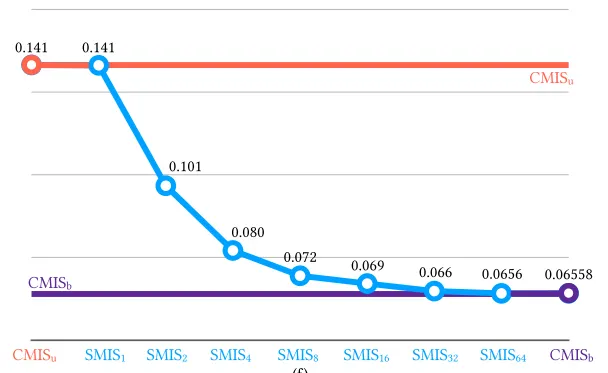
The new estimator is biased to approximate the estimator of CMIS, but eventually unbiased to approximate the original integral. Given n samples, SMIS requires PDF computation in the denominator. This requires much overhead. Therefore, one should find a balance for total samples, how much samples we require for approximation ( and how much realization do we use (.
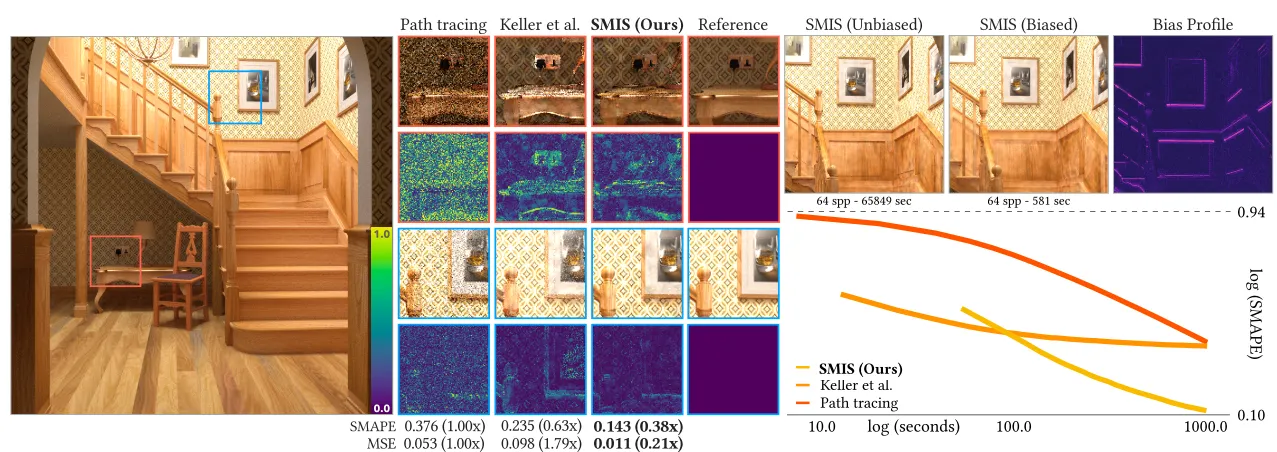
Path-space filtering (Path Reuse)
Formulation of CMIS and SMIS can be used for path-space filtering. Unlike previous methods, this method gives both better convergence and unbiasedness.
We can formulate the rendering a pixel with light transport of uncountable infinite path space by decomposing a path into two subpaths (prefix, suffix) = as below.
Supposing we have paths , we want to reuse suffices to link a given prefix .
Previous works formulate the estimator as below.
And approximate the weighting function.
We can formulate this problem into CMIS.
And the CMIS estimator can be approximated as SMIS estimator below.
Unlike previous work [Keller et al. 2014], this work weighs paths(samples) based on sampling densities (balance heuristics). Previous work weighs samples based on similarity in surface (position).